一般我們在做機器學習任務時,在模型裡計算的資料型態採用的是 float32 (即佔用32的bits或4個bytes),而 Nvidia 與 Baidu 一起發了一篇論文 Mixed Precision Training ,提出了一種訓練方式叫混合精度(Mixed precision),即訓練過程中同時使用單精度(float32)和半精度(float16)。
在 Tensorflow 的文件中提到,若要開啟雙精度訓練,只需要設定一個 global flag 即可。
mixed_precision.set_global_policy('mixed_float16')
如下範例,在開啟此模式後,可以看到 dense 本身的權重值仍是 float32,但是計算和輸出變成 float16。
inputs = keras.Input(shape=(784,), name='digits')
dense1 = layers.Dense(num_units, activation='relu', name='dense_1')
x = dense1(inputs)
print(dense1.dtype_policy)
print('x.dtype: %s' % x.dtype.name)
print('dense1.kernel.dtype: %s' % dense1.kernel.dtype.name)
產出:
<Policy "mixed_float16">
x.dtype: float16
dense1.kernel.dtype: float32
最後還有一個重要的一點,因為開啟混合精度後,所有的計算預設會使用 float16,包括模型的最後一層 softmax,但我們會希望最後的 softmax 精度越高越好(越準確),因此我們要在模型最後的 softmax 中,設置 dtype='float32' 指定輸出為float32。
(略)
x = layers.Dense(10, name='dense_logits')(x)
outputs = layers.Activation('softmax', dtype='float32', name='predictions')(x)
簡單解釋完上述概念後,我們今天要來實驗的內容就是開啟混合精度後,對我們的模型訓練有什麼影響?
實驗一:用混合精度訓練 mnist
mixed_precision.set_global_policy(mix_policy)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, [3, 3], activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.Conv2D(64, [3, 3], activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Softmax(dtype='float32')) # float32
print(f'{model.layers[1].name}:{model.layers[1].dtype_policy}')
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train_tf,
epochs=EPOCHS,
validation_data=ds_test_tf,
)
產出:
loss: 0.0475 - sparse_categorical_accuracy: 0.9851 - val_loss: 0.0311 - val_sparse_categorical_accuracy: 0.9899
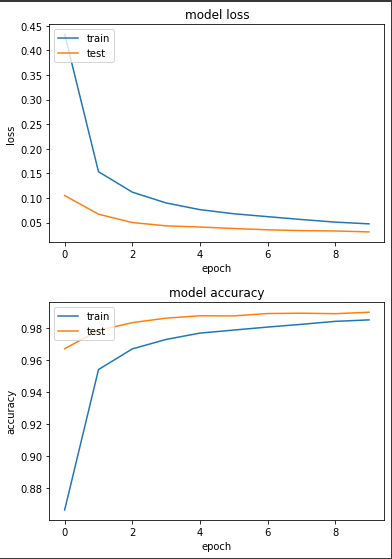
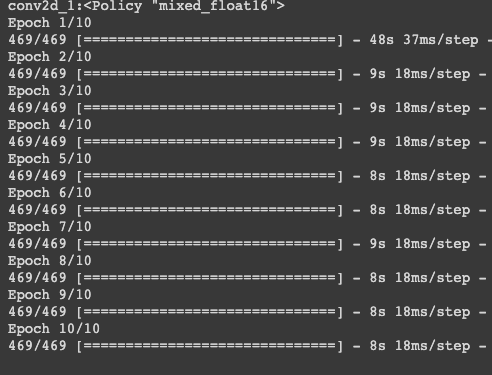
可以看到每次 epoch 平均花費8秒多。
實驗二:用單精度訓練 mnist
mixed_precision.set_global_policy(f32_policy)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, [3, 3], activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.Conv2D(64, [3, 3], activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Softmax(dtype='float32')) # float32
print(f'{model.layers[1].name}:{model.layers[1].dtype_policy}')
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train_tf,
epochs=EPOCHS,
validation_data=ds_test_tf,
)
產出:
loss: 0.0496 - sparse_categorical_accuracy: 0.9845 - val_loss: 0.0310 - val_sparse_categorical_accuracy: 0.9893
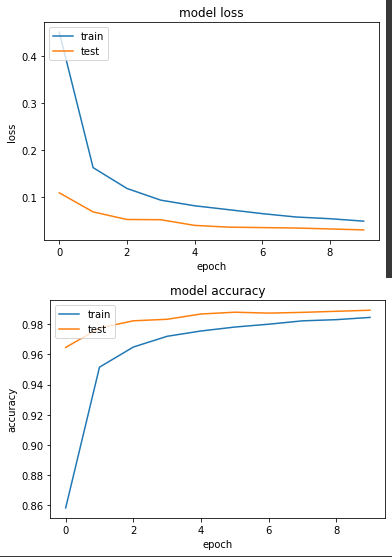
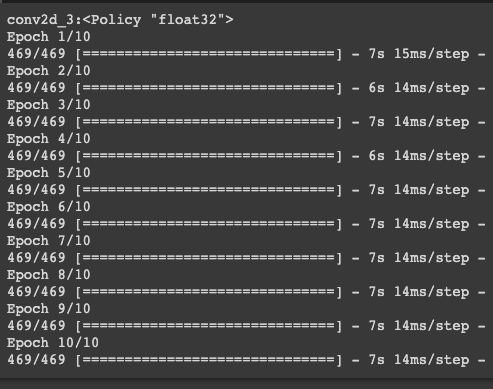
每次 epoch 花費7秒左右,跟預期的不太一樣,使用混合精度結果訓練比較慢。
實驗三:用混合精度訓練 oxford_flowers102 (訓練程式碼都相同,以下皆省略)
loss: 4.2232e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4107 - val_sparse_categorical_accuracy: 0.8853
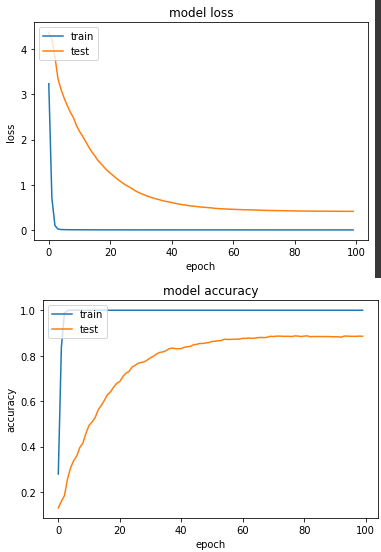
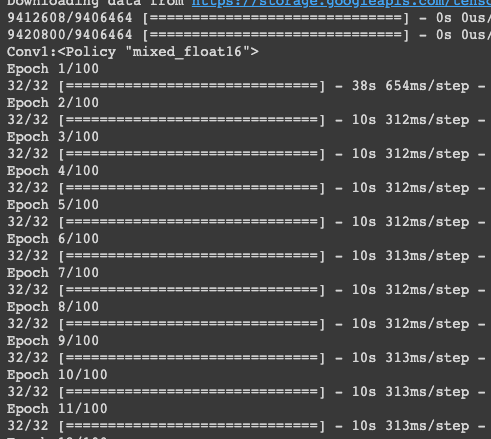
每次 epoch 花費10秒左右
實驗四:用單精度訓練 oxford_flowers102
loss: 4.8664e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4102 - val_sparse_categorical_accuracy: 0.8843
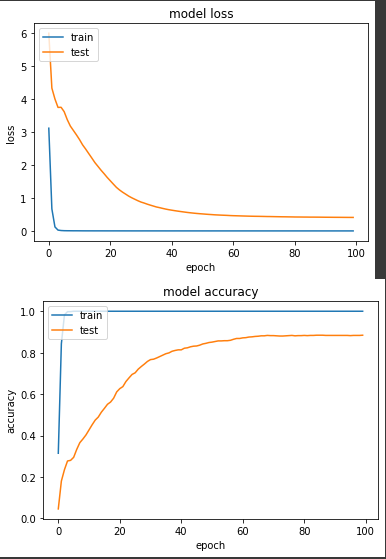
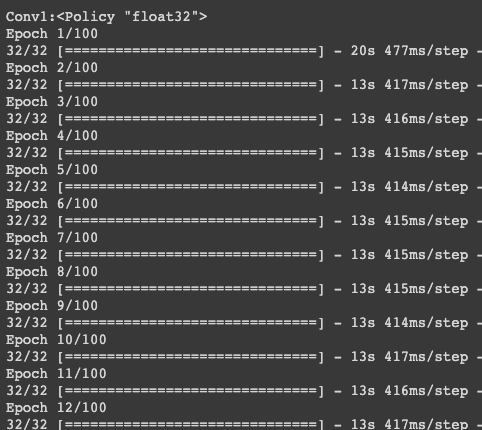
每次 epoch 花費13秒,混合精度勝!
實驗五:用混合精度訓練 cifar10
loss: 0.0448 - sparse_categorical_accuracy: 0.9843 - val_loss: 0.4190 - val_sparse_categorical_accuracy: 0.9001
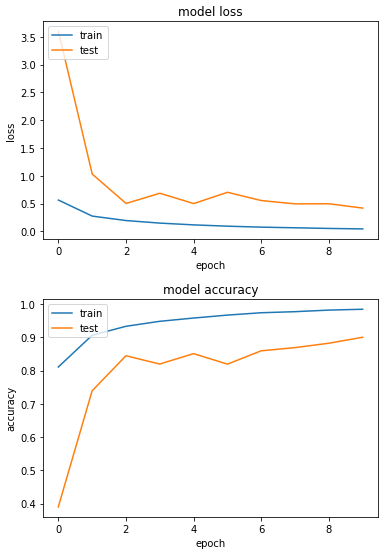
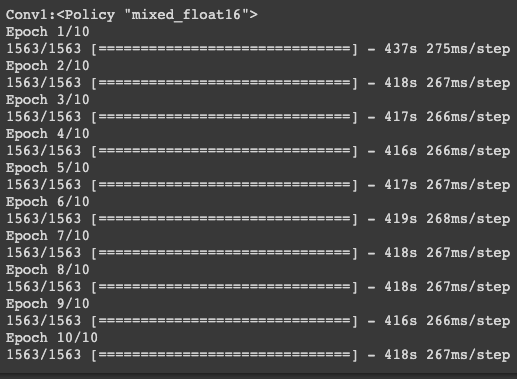
每次 epoch 花費在417秒左右
實驗六:用單精度訓練 cifar10
loss: 0.0419 - sparse_categorical_accuracy: 0.9859 - val_loss: 0.3610 - val_sparse_categorical_accuracy: 0.9091
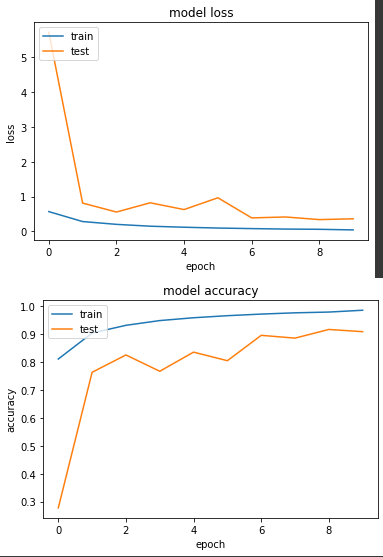
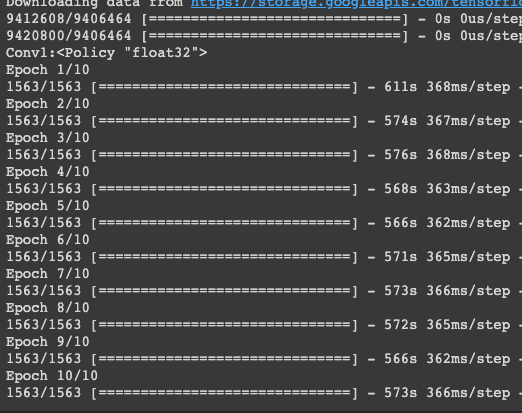
每次 epoch 花費秒數在566~574區間,仍是混合精度勝!
綜觀以上結果,我們發現兩者準確度都差不多,但是在模型比較複雜的狀況下,使用混合精度節省了不少時間,因此在使用 GPU 的狀況下,都非常推薦將混合精度開啟。

